When the user asks a question in a RAG project, by default the complete content of this RAG project will be considered for the generation of an answer. However, often the user has good intuitions which documents may contain the right answer and also, which documents should not be considered for the answer generation.
The user can therefore apply filters on the content: Only content that matches the selected filters will be used to generate the answer.
By default the document’s metadata will be available as filter: So if in a project, the documents carry metadata for instance to express the topic, the source, the language or other kinds of metadata, these can be selected as filters. Or order to do so, select the “Question Answering” item in the menu on the left of a RAG project and then select the “Filter” tab. You will see the documents’ metadata to chose from:
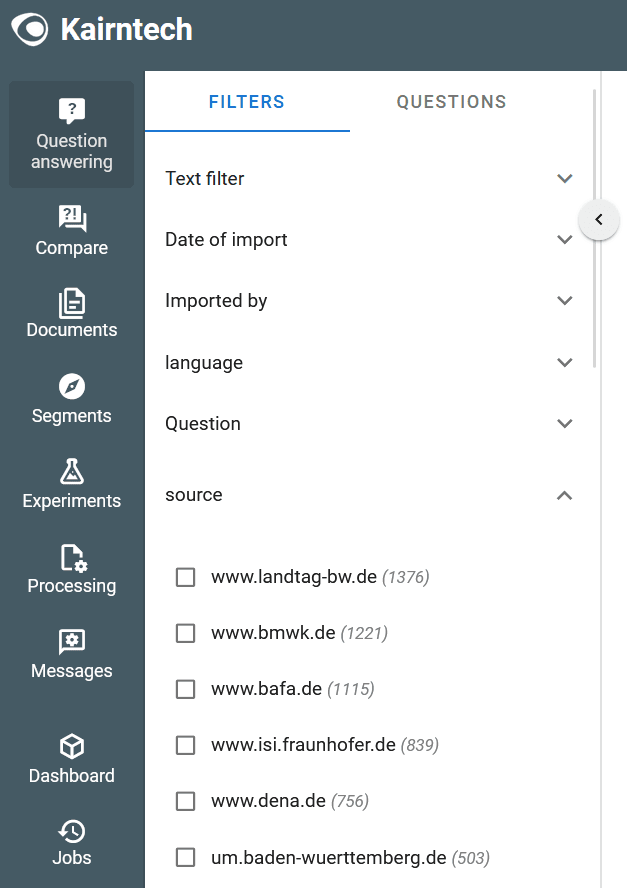
In the example above, the content has a “source” metadata field. The users can now select from which sources the content may come from that will be used to generate an answer to the question. Note that selecting several values within one metadata fields will be interpreted as a logical OR: Documents that satisfy either one of the selected values will be used.
Note that when selecting filters from different Metadata fields, they will logically be connected with an AND. So content must satisfy each of the constraint expressed in each of the different metadata fields in order to get selected. Example: If the documents carry a SOURCE field with values “Africa”, “America” and “Asia” and a YEAR field with values “2024” and “2025”. Then selecting SOURCE:Africa and SOURCE:Asia and YEAR:2025 will result in all documents to get selected that have SOURCE “Africa” OR “ASIA” and also that are from the year “2025”.
This allows the user to determine the scope of the answer in a fine grained way: Perhaps a project contains content from different states (german Bundesländer), but for the next answer the user is interested only in answers on the basis of content from Bavaria. Properly maintained metadata will allow to do precisely that. (In order to benefit from this, make sure, that you import your content with the required metadata for your case: Use the json format to prepare your documents with the required metadata.)
Above we said, that the content metadata will be available as filters. This requires some additional information as not all metadata by default will be offered as filters: For reasons of efficiency and usability, some constraints are applied when translating metadata into filters, that may lead to metadata being excluded. This is not accessible for the user – in case you need this process to be modified, contact your Kairntech administrator.
More specifically the following set of constraints is applied:
- Metadata values beyond a maximal length (default 1014 characters) will be excluded
- Metadata fields with more than a maximum number of different values (default 100) will be excluded
- The user interface will display metadata fields only up to a maximum number (default 20)
- Metadata values that are unique or almost unique (little variation) across documents will be excluded (e.g. if each document carries a unique URL, this will be excluded as it is considered not a reasonable filter)